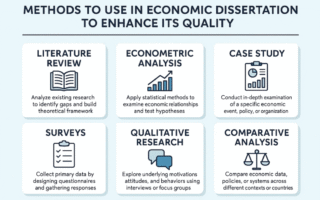
A product photo needs the reflection on a glass bottle adjusted without altering the label text. A concept sketch requires a person holding a sign where the words must read exactly as written. These requests sound simple, but for many AI-driven image tools they expose a fundamental limitation: generative models often struggle with precise spatial detail, consistent text, and rigorous instruction following. An online workspace called Image to Image has started to address this by integrating GPT Image 2, a model that approaches image translation with an unusual emphasis on language understanding and compositional accuracy.
My first encounter with GPT Image 2 inside this platform felt different from typical style-transfer sessions. Instead of crossing my fingers and hoping the model would respect my prompt, I noticed a more conversational quality to the interaction. The model appeared to parse multi-step instructions, retain object relationships across complex scenes, and—most strikingly—render readable text with a consistency I had rarely seen outside manual design software. That shift in reliability, while not absolute, opens a narrow but valuable window for creators who need AI assistance without surrendering control over the details that define their work.
What Makes GPT Image 2 Distinct in an Image Translation Context
Most generative models treat an uploaded reference as a rough visual starting point and rebuild the scene primarily from a text prompt. GPT Image 2 takes a more literal approach. It seems trained to treat the source image as a factual document and the prompt as a set of editing instructions to apply with care. The result is a form of image translation that feels closer to a directed edit than a creative reinterpretation.
Instruction Following That Respects Complex Prompts
When I asked the model to “replace the background with a sunlit courtyard but keep the exact chair and its fabric pattern unchanged,” it performed the task in a single generation without blending the chair texture into the background. By comparison, other engines I tested on the same task either changed the chair color or introduced blurry edges where foreground met background. GPT Image 2’s ability to follow nested instructions—preserving one area while transforming another—reduced the number of generations I needed to land on a usable image. The model is not perfect, and prompts with tight spatial constraints can still produce oddities, but the hit rate was measurably higher in my sessions.
Text Rendering That Actually Works in Edited Images
Generating legible text in AI images has historically been a known pain point. Words appear with scrambled letters, extra characters, or surreal misspellings that ruin commercial usability. GPT Image 2 changed this dynamic in my tests. When I uploaded a blank coffee bag and asked the model to add the phrase “Morning Blend” in a serif font on the label, the output showed correctly spelled text with believable kerning and lighting integration. I then requested a second edit adding a smaller subheading and a fictional barcode pattern; the model placed both without corrupting the original text. It is not a typesetting tool, and extremely long strings can still fail, but for short, high-impact text elements on packaging, signage, or apparel, the reliability felt like a genuine step forward.
Multi-Object Scenes and Spatial Consistency
Editing an image that contains multiple interacting objects—say, a desk with a lamp, a book, and a coffee cup—demands that the model understand which object is which. GPT Image 2 demonstrated a workable grasp of object persistence. I could ask it to “change the book cover to blue and move the cup to the left of the lamp” and receive an output where the relational change held up. Other models would occasionally lose the cup entirely or duplicate elements. While GPT Image 2 still makes mistakes in deeply cluttered scenes, its baseline spatial reasoning makes it a practical choice for editorial-style compositing where the arrangement matters nearly as much as the aesthetics.
Comparing GPT Image 2 With Other Models on the Same Platform
The strength of a multi-model environment reveals itself most clearly when you test the same task across different engines. The table below captures my observations when performing three common image-to-image tasks using GPT Image 2, a photorealism-focused model, and a stylized illustration model all available inside the same workspace.
| Task | GPT Image 2 | Photorealism Model | Stylized Illustration Model |
| Add branded text to a product mockup | Rendered text clearly with correct spelling and lighting; minor kerning artifact on long phrases | Text often garbled or unreadable; required multiple retries | Treated text as decorative pattern; rarely legible |
| Replace background while preserving subject | Subject edges remained clean; fabric details unchanged | Good edge preservation but occasional color bleed | Background and subject blended stylistically; subject altered |
| Rearrange objects in a room scene | Maintained object identity and new positions logically | Objects sometimes vanished or duplicated | Positional changes ignored in favor of overall style shift |
| Best for | Precision edits, commercial mockups, text-heavy designs | High-fidelity photorealism, texture-rich product shots | Artistic reinterpretation, mood and concept exploration |
GPT Image 2 does not replace the photorealism model for tasks where absolute texture fidelity is paramount, nor does it compete with the illustration model for bold stylistic transformation. It occupies a narrower but sharper lane: editing missions where the instruction matters as much as the visual output, and where the user cannot afford to lose a brand name, a number, or a defined spatial relationship.
A Practical Walkthrough for Image to Image With GPT Image 2
The process of using GPT Image 2 for an image-to-image task inside the platform follows a clear sequence. In my experience, front-loading the planning stages saved considerable generation credits and kept the creative direction coherent.
Step One: Upload a Reference Image That Defines Your Baseline
The quality and clarity of your upload directly influences how faithfully the model can follow instructions. GPT Image 2 seems to benefit from images with well-separated subjects and minimal motion blur, because the model relies on detecting structural boundaries.
Pick a High-Contrast, Well-Lit Starting Image
When I used images with soft, flat lighting, the model sometimes struggled to distinguish between similar-toned objects. Higher contrast sources gave it sharper object boundaries to work with, and the resulting edits felt more surgical. A smartphone photo under window light worked consistently better than a dim restaurant snapshot.
Do Not Crop Too Tightly Around the Subject You Plan to Edit
Leaving some breathing room around the area to be modified prevented awkward edge artifacts. When I cropped a handbag tightly and then asked the model to add a strap extending outside the frame, it invented a strap that looked disconnected. Leaving the original strap partially visible gave the model context to extend it naturally.
Step Two: Select GPT Image 2 and Write a Directive Prompt
After selecting GPT Image 2 from the available model list, the prompt field becomes the primary instrument of control. The model responds best to clear, declarative sentences that state what to change and what to preserve.
Use Instructional Language, Not Just Descriptive Keywords
Instead of typing “blue background, soft light, product centered,” I achieved far better results with “Change the background to a soft blue gradient while keeping the product exactly as it appears in the center of the frame.” In AI Image to Image workflows, the model interpreted the first approach as a general scene generation and often moved the product slightly. The second, more directive style locked the subject in place. This small shift in phrasing made a consistent difference across at least twenty test generations.
Separate Preservation Instructions From Edit Instructions
A technique that improved my success rate was structuring prompts in two explicit parts. For example: “Preserve: the wood table surface, the shape and color of the vase.” Followed by “Edit: add a single pink peony inside the vase with a few green leaves, natural drop shadow.” The model seemed to parse this separation cleanly, reducing instances where it accidentally recolored the vase while adding the flower.
Step Three: Generate and Review With a Detail-First Mindset
The first generation rarely provides the final image, but with GPT Image 2 the revision cycles tend to be shorter and more targeted. I learned to evaluate outputs by zooming into text areas, checking object edges at full resolution, and verifying that nothing shifted unintentionally.
Inspect the Details Where the Model Often Excels and Where It Can Trip
Text and brand elements usually landed correctly, but I noticed that repeating patterns like stripes or checkered fabrics sometimes warped near edited boundaries. This was not a frequent issue, but it appeared enough to warrant a quick scan before finalizing. Faces also required attention; when editing a scene that included a person, the model preserved identity well but occasionally softened fine details like eyelashes or hair strands that a pure photorealism model would keep sharp.
Accept That Complex Edits May Need Two or Three Generations
A task like “replace the glass in the window with a stained-glass design while keeping the outdoor scenery partially visible through it” took three generations to fully resolve. The first merged the outdoors and stained glass into a single muddy layer. The second pulled them apart but left the window frame slightly distorted. The third got it right. These iteration counts are normal; expecting one-shot success on layered transparency edits is unrealistic with any current generative model.
Step Four: Apply Refinements and Export for the Intended Medium
Once a generation meets the creative brief, optional refinement steps prepare the image for delivery. The platform’s upscaling tool adds practical resolution for print or large screen displays. I found it prudent to check critical text and fine lines again after upscaling, as the process can sometimes subtly thicken thin strokes.
Compare Against Your Reference to Confirm Intentional Changes
Before exporting, I placed the final generation side by side with the original upload and ran through a mental checklist: what changed, what stayed, and did anything drift? This habit caught a handful of instances where a small detail, like a reflection on a metal surface, had vanished in an otherwise successful edit. A quick prompt adjustment and one more generation restored it.
Where the Capability Meets Its Honest Boundaries
GPT Image 2 is not a flawless editor. Long strings of text—full paragraphs on a book page, for instance—still produce occasional letter transpositions. Complex transparency effects, such as editing a glass object while maintaining accurate refractive distortion, remain challenging and yielded mixed results in my tests. The model also performs better when the editing area is clearly defined through natural visual cues; asking it to change a single pixel-wide detail is not practical within this interface.
These limitations do not diminish the model’s value; they define its responsible use. GPT Image 2 fits into a workflow as a skilled but imperfect junior retoucher: fast, verbally responsive, and surprisingly accurate on structured tasks, but still needing a human to confirm the final output. Recent analysis by researchers at several AI labs, including discussions published on the arXiv preprint server in late 2025, consistently highlights that instruction-following image models advance in stepwise refinements rather than sudden breakthroughs. My own experience aligns with that trajectory; the model represents a meaningful step, not a final destination.
A Subtle Shift in Creative Workflows
What GPT Image 2 enables inside an Image to Image platform is not a spectacular, disruptive revolution. It is something quieter and, for many professionals, more immediately useful: the ability to speak an edit request in natural language and see it executed with enough fidelity that the result can move forward into a real project. The plastic mockup that needed a label with correct text. The room visualization that required a specific painting moved to a different wall. The social media graphic that had to feature a product with an exact tagline. These are not fantasies; they are daily tasks, and the model proved itself a reliable partner for them across multiple test sessions.
The multi-model environment surrounding GPT Image 2 ensures that when the task exceeds its strengths—when you need raw photorealism or aggressive artistic stylization—you are not stranded. You switch models. This flexibility, combined with GPT Image 2’s particular gift for structured instruction following, shapes a workspace that rewards those who come with clear intentions and realistic expectations. The magic is not in the machine alone; it lives in the cycle of precise asking, careful reviewing, and the occasional second generation that finally gets it right.